发布日期:2026-02-05 18:28 点击次数:164
Gemini 3的训练涉及预训练、后训练等多个阶段,具体如下:
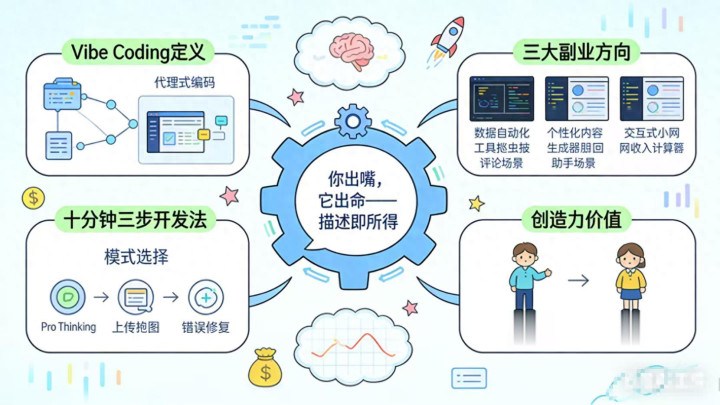
预训练阶段
- 数据筛选:采用“三重滤网”体系对数据进行筛选。
第一层通过自研工具DataPurifier进行基础清洗,剔除乱码、机器翻译腔等低质内容,减少无效token 63%。
第二层引入“知识密度指数(KDI)”进行价值评估,仅保留KDI>0.8的数据。
第三层进行场景适配,按任务类型标注数据,如代码、多模态、长文本等,避免模型知识过于泛化。
- 数据增强 :增加图像和文本混合数据的token预算,引入更多的多语言数据,包括单语和并行数据,并采用特定策略来解决语言表示不平衡的问题,提升模型的语言覆盖范围和多语言处理能力。

- 模型架构 :Gemini 3大体上沿用了Transformer MoE架构,并在此基础上进行了多项创新性和优化措施,如采用局部与全局自注意力层交替配置的策略,平衡处理长文本时的内存效率与模型性能。
后训练阶段

- 蒸馏:从较大的指令模型蒸馏到Gemini 3预训练检查点,每个token会采样256个logits,并按照模型的概率分布进行加权,引导小白对模型学习更优的分布。
- 强化学习:利用人类反馈强化学习,使模型预测与人类偏好保持一致;借助机器反馈强化学习增强数学推理能力;通过执行反馈强化学习提升编码能力。

Gemini 3的训练涉及预训练、后训练等多个阶段,具体如下: 预训练阶段 - 数据筛选:采用“三重滤网”体系对数据进行筛选。 第一层通过自研工具DataPurifier进行基础清洗,剔除乱码、机器翻译腔等低质内容,减少无效token 63%。 第二层引入“知识密度指数(KDI)”进行价值评估,仅保留KDI>0.8的数据。 第三层进行场景适配,按任务类型标注数据,如代码、多模态、长文本等,避免模型知识过于泛化。 - 数据增强 :增加图像和文本混合数据的token预算,引入更多的多语言数据,包括...
Gemini 3的训练涉及预训练、后训练等多个阶段,具体如下: 预训练阶段 - 数据筛选:采用“三重滤网”体系对数据进行...
北京时间12月5日鹈鹕主场对阵森林狼,全场比赛结束鹈鹕以116-125输给了森林狼。鹈鹕在本赛季的战绩糟糕,如今锡安又遭...
作者:文学之都客 2025年11月8日 图片 茶道一词最早见于唐代诗僧皎然有一首杂言古体诗《饮茶歌·诮崔石使君》云“越人...
图片 本站仅提供存储服务,所有内容均由用户发布,如发现有害或侵权内容,请点击举报。...